どうやってUE4で透明な氷を作るか
原文:
氷塊は生活に欠かせないものですが、エンジンで氷の質感や物性を復元するのはかなり難しいと思います。私も簡単な方法でシミュレーションしただけですが、制作プロセスを紹介いたします。まずは近距離での写真をご覧ください。

比較的透明な氷

透明度の低い氷

視点による変化
Shader全体に使用されたのは、照明のないMaskのShading Modelです。主な制作手順は、次の部分に分けることができます。
内部体積(Internal Volume)、表面反射、半透明シミュレーション、屈折、半透明の影、およびいくつかの色の変化。
内部体積制作
内部体積の制作は記事「UE4 で raymarch を使ってメッシュ水 (サンプリング スタンプ) (中国語注意)を如何に実装するか」と同じなので、ここでは詳しく説明しません。
コードを知らない方は、Parallax Occlusion Mappingで実装しましょう. パフォーマンスはより消費されますが、効果は同じです。

Raymarch Perlin Noise 後の効果

パラメータ設定
内部体積 ノード グラフについては、記事「UE4 で raymarch を使ってメッシュ水 (サンプリング スタンプ)(中国語注意) を如何に実装するか」(サンプリング テクスチャ) を参照できます、スタンプを Perlin Noise に置き換えてください。
半透明のシミュレーション
それでは、最も重要な部分に移ります。照明のない マスク モードを使用しているため、半透明ミュレーションは、Cubemap をオブジェクトに貼り付ける方法を使いました。次の記事においては、低層を変更して実装しましたが、こちらの実装は少し高層に位置しますけれども、原理は大体同じです。興味がある方は参考してください。
リアルタイムCubemapの場合は、Scene Capture Cubeを使ってキャプチャする必要があるが、静的な場合は、シーンを直接Cubemapにして貼り付けるだけで良い。新しい BP Actorを作った後、新しいカメラを作成します。それから、Cube Render Targetを作って、Cube Textureをカメラのスロット (throttle)に挿入します。

Cubeカメラ

カメラスロット
マテリアルに戻ると、最初にCubeスタンプ(つまり、新しく作成されたCube Render Target) をマテリアル エディタに入れ、次に UV ポートをCamera Vectorに接続し、最後にそれを自己照明に出力します。以下は逆効果です。

UV としてのCamera Vector

Z 軸の逆効果
それでは、最初に Camera Vector の b 軸を逆にして効果を確認してみましょう。

逆カメラ ベクトル B 軸

B軸逆の効果
ほとんど同じく見えるでしょう?しかし、角度が間違っているため、Cubemap を回転させる必要があります。ここで RotateAboutAxis を使用して回転させます。回転軸は 0, 0, 1 (z 軸) で、positionは Camera Vector で、回転後にCamera Vectorを追加します。 (Camera Vector を基準に回転しているため)、最後に Normalize (UV 空間は 0-1)、Z 軸を反転して Cube Texture の UV に接続するだけでよい。回転角度は 270 度です。(マテリアルエディタではラジアンで計算されるので、360で割って度単位に変換します)。

透明をシミュレートする

透明の効果をシミュレートする
まあまあ良いですね。でも、Cubemapのため、完全にマッチすることはできなくて屈折の高いオブジェクトにしか適していません。また、カメラでCubemapをキャプチャすると、それ自体もキャプチャされます. それをカーリングする方法については最後に説明します.
反射
反射は非常に簡単に言えます。同じくCube Texture (つまり、新しく作成されたCube Render Targetです) を使います。続いては、Reflect Vectorを使用して UV に接続します。最後に、Lerp で反射と透明度の混合比を制御します。このように、透明度へのコントロールが実現されました。

混合反射と半透明

Lerpによる混合比率の制御
混色
内部体積と上記の効果が得られたら、それらを混ぜます。内部体積をMaskとして 2 つの不透明度を混合し (実は内部体積と透明をシミュレートする Lerp 値です。ただ2 つの Lerp が必要で、反射効果は最後に混合されます)、フレネルを使用して遠方と近方の不透明度を制御します、近方は透けて見えますが、遠方は透けません。

シミュレート半透明と内部体積による透明度の混合

透明度混合

透明度と内部体積をブレンドした結果

パラメータ設定
上記の効果を作成した後、引き続き上部反射の効果を混合し、フレネルで反射強度の変化 (実際にはroughnessの変化を指します) を制御します。
 混合反射効果の反射値を 0.9 に設定する
混合反射効果の反射値を 0.9 に設定する

反射後を効果を混合した後、ハイライトが出てきました。
最後に、色の上にフレネルのレイヤーを追加すれば完成です。
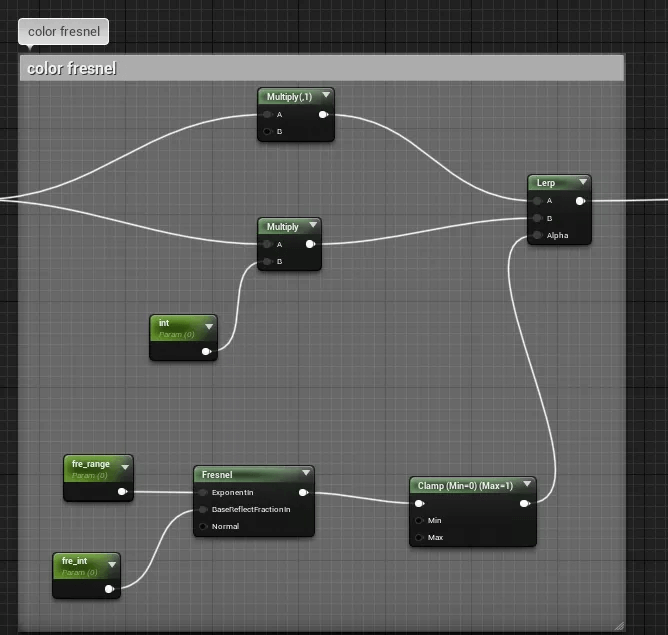
カラーフレネル

カラーフレネル効果
屈折
屈折も簡単です。その原理は半透明のCube Textureを乱すことです。半透明の UV の RG 軸にスタンプを乗算するだけで済みます.もちろん、内部堆積を適応するため、内部体積の UV を屈折マップの UV として使用できます。

屈折効果 (このNoise Mapはあまり良くありません)
基本的な効果ができました。それから、偽の半透明の影を作成します。
半透明の影
この部分はDither Mask法を使用します。次にShadow Pass Switchを使用して現在の影を置き換えます (実際、Dither後のモデルは影を投射するモデルとして使用されます)。 ViewSpace の B 軸でPixel Normal (つまり、モデルの地面での投影) をとり、abs から負の数を取り除いて反転してフレネルのような効果を出しますが、フレネルのように視点によってすごく変化していくように見えません。 Power で範囲をコントロールし、最後に Dither に出力し、Shadow Pass Switch に接続してから Opacity Mask に出力すると、偽の半透明の影 (Dither 影) が得られます。

半透明の影 ノード

Pixel Normal で作成された効果

半透明の影

透明度の変化

translucentモードでの透明変化
最後に全体的なノード示します:

全体のノード

パラメータ設定
追加の質問: カメラで特定のオブジェクトのみをキャプチャするにはどうすればよいですか?
この質問がよく聞かれました。ここでは、特定のオブジェクトのみをレンダリングするように設定する方法を説明します。

カーリングする前に自身が撮れてしまう
まず、新しいレイヤーを作成し、表示するものを選択してレイヤーに追加します。

レイヤーのアウトライン

表示Actorを追加
BP のカメラでは、リスト オブジェクトのみを表示するように設定します。

カメラを設定する
次に、リストをカメラに渡し、freshを使って手動更新します。それは、非play状態のマテリアルでは Cube Texture がリアルタイムで更新されないためです。

リストをカメラに渡す
最後に、新しく作成した Actor Layer 変数のレイヤー名を指定して、選択したレイヤーのオブジェクトのみを表示します。

指定画層
自分自身をカーリング後の効果
UWA公式サイト:https://jp.uwa4d.com
UWA公式ブログ:https://blog.jp.uwa4d.com
UWA公式Q&Aコミュニティ(中国語注意):https://answer.uwa4d.com
UE4でどのように漣の効果を作るか
漣という効果を作ってみた人が多いと思います。実装方法はいろいろありますが、ここではCustomノードを使い、アルゴリズムで法線を生成する方法を採用します。
まずはUVで擬似ランダムのメッシュを作り、一つ一つのメッシュは単独的なUVです。ただし、異なる階調値があります。そして、メッシュの中心でサイズが違う同心円を生成します。その後、スケーリングとエッジブレンディングを行います。
ASTC テクスチャ圧縮形式
一、ASTC テクスチャ圧縮形式の紹介
ASTC は、OpenGL ES 3.0 の出現後、2012 年半ばに作成された、業界をリードするテクスチャ圧縮形式です。その圧縮ブロックは4×4 から 12×12 まで、最終的に1ビット未満毎ピクセルに圧縮できます。それに、多くの圧縮率を選択することができます。ASTC 形式は RGBA をサポートし、 2 の累乗のアスペクト比が1の寸法とサイズ要件のないNPOT (非 2 の累乗) テクスチャに適しています。

ASTC 4×4 ブロック圧縮形式を例にすると、1ビット8bits毎ピクセルです。1024×1024 テクスチャの圧縮サイズは 1MB です。
ASTC は、圧縮の品質と容量において大きな利点があります。
ドキュメントに詳細なテスト データがあります:
https://developer.nvidia.com/astc-texture-compression-for-game-assets
二、対応機種
1、iOS
Apple は A8 プロセッサから ASTC へのサポートを開始しました。これは、iPhone6 および iPad mini 4 より上の iOS デバイスでサポートされていますが、2014 年の iPhone 5s および iPad mini 3 より前のデバイスではサポートされていません。
2、アンドロイド
Android の主流の圧縮形式は、ETC2 から ASTC に移行しています。
Android ASTC 形式のサポートに関する Unity の公式説明:
https://docs.unity3d.com/Manual/class-TextureImporterOverride.html

公式ドキュメントでは、ASTC の GPU サポートについて言及しています。OpenGL ES 3.1 をサポートするすべての GPU と、OpenGL ES 3.0 をサポートする一部の GPU です。
OpenGL ES 3.0 GPU の不確実性を考慮して、現在のユーザーの割合が高いいくつかのローエンドデバイスで ASTC 形式の互換性テストを実施し、さらにテストのために、いくつかの占用率が低いGPU 型番を追加しました: Mali-G71、Adreno 306、Adreno 308、Adreno405 (テスト時間 2020.5.21):

市場に出回っているほとんどの機種は OpenGL ES 3.1 以上をサポートしています. GPU 構成の低いいくつかのモデルは OpenGL ES 3.0 をサポートしていますが、ASTC 圧縮形式をサポートしていません。2020 年 4 月の市場シェアは 1.5% 未満です。個人的な観点から見れば ASTC 圧縮形式が広く使用されても大丈夫です。
補足:Unity 公式ドキュメント バージョン 2018.4 で ASTC 圧縮形式のサポートが紹介されました。
Texture Compression ASTC Platform Support:tvOS (all), iOS (A8), Android (PowerVR 6XT, Mali T600 series, Adreno 400 series, Tegra K1)
三、圧縮形式の選択
前文で、さまざまな ASTC 形式の Bits Per Pixel (ビット毎ピクセル) について学びました。より直感的に理解するために、例として圧縮歪みが発生しやすいテクスチャを使用します。
1、ASTCフォーマットとETC2フォーマットの圧縮結果と容量の比較

上の図からわかるように、512×512 テクスチャ マップ (アルファ チャネルがない、Mipmap をオンにする) の容量は 1MB であり、ETC2 4 ビットに圧縮した後の容量は 170.7KB であり、明らかな歪みがあり、ASTC 6×6 への圧縮後の容量はは 154.7 KB で、明らかな歪みはありません。ASTC 6×6 の容量は ETC2 4 ビットよりも小さく、圧縮品質は ETC2 4 ビットよりも高くなっています。

上記の図からわかるように、ASTC 8×8 に圧縮した後の容量は 85.4KB で、ETC2 4 ビットの約 50% であり、圧縮品質は ETC2 4 ビットよりも高くなっています。
2、アルファ チャネルなし、RGB 24 ビット/ピクセル圧縮形式の選択

上の図からわかるように、512×512 サイズのマップ (アルファ チャネルなし) は、ASTC 6×6、ASTC 8×8、および ASTC 10×10 に圧縮された後に明らかな歪みがなく、ASTC 8×8 に圧縮された後の容量は ASTC 6×6と比較して約 44.8%減少します。 ASTC 10×10 に圧縮すると、ASTC 8×8 に比べて容量が約 33.7% 減少します。
法線マップを例に取ります。

上の図からわかるように、ASTC 4×4 に圧縮された 512×512 のサイズの法線マップには明白な歪みがなく、ASTC 5×5 に圧縮され、歪みは肉眼で見ることができ、ASTC 6×6 に圧縮された歪みは明らかです。

例として、顔のテクスチャを取り上げます。

上の図からわかるように、ASTC 6×6 に圧縮すると明らかな歪みはなく、ASTC 8×8 に圧縮すると歪みが肉眼で確認できます。
結論: アルファ チャネルのないテクスチャの推奨圧縮形式は、ASTC 8×8 です。テクスチャが法線マップの場合、推奨される圧縮形式は ASTC 5×5 です。より高い要件を持つテクスチャ (顔、シーン グラウンドなど) の場合、圧縮形式を ASTC 6×6 に設定し、法線マップを ASTC 4×4 に設定できます。
その結論とNV ドキュメントデータを比較したら、

薄い緑はベンチマークの推奨を示し、濃い緑はより高い要件の推奨を示します. 唯一の違いは、通常のテクスチャの圧縮に ASTC 6×6 を選択するか、ASTC 8×8 を選択するかです。個人的な観点から, 8×8 の推奨指数は0のはずです。
3、アルファ チャネル、RGBA 32 ビット/ピクセルの圧縮精度の選択

上の図からわかるように、ASTC 5×5 に圧縮すると歪みが肉眼で確認でき、ASTC 6×6 に圧縮すると明らかな歪みがあり、ASTC 5×5 に圧縮するとASTC 4×4 と比較して容量が約 34.9 % 減少します。 同じ圧縮形式の下で、アルファ チャネルを使用した圧縮の品質は、アルファ チャネルを使用しない場合よりも大幅に低下します。
結論: アルファ チャネルを持つテクスチャの推奨圧縮形式は ASTC 5×5 です。より高度な要件 (特殊効果、UI など) を持つテクスチャの場合、圧縮形式を ASTC 4×4 に設定できます。
結論は、NV ドキュメント データの比較と一致しています。

4、圧縮に対するアルファチャンネルの有無の影響
同じ圧縮形式の下では、テクスチャの容量は同じままです。アルファ チャネルの有無は圧縮結果に大きな影響を与え、アルファ チャネルを使用したテクスチャの圧縮品質は低下します。

上の図からわかるように、アルファ チャネルを含む 32 ビット イメージとアルファ チャネルを含まない 24 ビット イメージでは、同じ圧縮形式を選択しても、圧縮結果は大きく異なります。

アルファ チャネルを含む 32 ビット イメージの場合、[インポート設定] で [アルファ ソース] を [なし] に選択すると、圧縮結果はアルファ チャネルがない場合と同じになります。
5、その他の問題
1) シェーダーへの影響
デフォルト テクスチャが「黒」の場合、テクスチャがデフォルトの場合、デフォルト値は (0,0,0,0) であり、A チャネルは 0 を読み取り、RGB ETC2 4 ビット フォーマットを使用する場合、A チャネルは 0 を読み取ります。 ASTC フォーマットでは、チャネル A は 1 として読み取られます。ここで、シェーダーのデフォルト値の考慮に注意を払う必要があります。
2) JPEG 形式はすでに非可逆形式です。JPEG で失われる精度は、ASTC 圧縮とは関係ありません。
3) テクスチャサイズについて。
圧縮形式が非 2 の累乗をサポートしている場合、ハードウェアが圧縮形式をサポートしている限り、NPOT テクスチャを使用できます。ただし、2 の累乗のテクスチャは他のサイズよりも優れており、ここには複雑なグラフィック要素があります。
参考記事:「2 の累乗でないテクスチャに対する OpenGL のサポートの基本原理は何ですか?」 (中国語注意)
簡単に理解すると、テクスチャは GPU 内のブロック単位で保存されます。メモリと帯域幅をできるだけ節約するために、圧縮形式もテクスチャをブロック的に保存します。再帰またはループでは、数値が 2 の累乗の場合、2 で割り切れ、商も 2 の累乗になります。 OpenGL API は 2 の累乗以外をサポートします。これは、使いやすさのために詳細が隠され、必要なストレッチ操作や塗りつぶし操作が内部で処理されるためです。したがって、特別な要件がない場合は、POT テクスチャを使用してみてください。また、作成時に実際のアプリケーション サイズに応じて作成して、高精度の圧縮から低精度の使用を避けるようにしてください。
4) テクスチャ自体にアルファ情報があるかどうかに関係なく、ASTC 圧縮のさまざまな設定によって圧縮サイズが直接決まります。テクスチャ リソースのパッケージ サイズを制御するかどうかは、ASTC 圧縮形式の仕様が適切かどうかに依存します. 結局、ASTC 8×8 への圧縮後の容量は、ASTC 6×6 と比較して約 44.8% 削減され (85.4KB 対 154.7KB)、ASTC 4×4 よりも約 300% 小さいのです (85.4KB 対 341.4KB)。そして通常、アルファ チャネルが空かどうかを確認します。これは、アルファ情報が冗長であるかどうか、および圧縮精度を低く設定する必要があるかどうかを判断するのに役立ちます。
5)ASTC 圧縮アルゴリズムはよりスマートで、より可変性の高いチャネル RGB または A に高い重みを割り当てます。モノクロ画像の場合、またはRGB チャネルのコンテンツが同じ場合、より低い「1ビット毎ピクセル」を使用して、良い効果が出られます。モノクロ画像の場合、R8 圧縮形式を使用する必要はありません。代わりに、RGB チャネルに同じ情報を入力し、ASTC 8×8 など、ASTC が低いピクセル比を選択できます。
6)プロジェクトの実際の使用では、法線マップの場合、ETC2 4 ビットの圧縮効果が ASTC 5×5 の圧縮効果よりも優れていることがわかりました。透過チャネルを持つマップの場合、ETC2 8 ビットがASTC 4×4よりも優れている場合があります。¥を以前のテストで比較見逃していました。さらに比較が必要であり、実際の状況に応じて選択します。
A チャネルの詳細がある場合は ASTC を選択し、A チャネルの詳細が少ない場合は ETC2 を選択します。
投稿者の に感謝します。
著者のホームページ: https://www.zhihu.com/people/ssiya-330
著者の許可なしに転載しないでください。
シェアすることは大歓迎です!
無断転載・二次配布は禁止となります。
何かご意見・ごコメントがございましたら、いつでもお気軽にお問合せください。
UWA公式サイト:https://jp.uwa4d.com
UWA公式ブログ:https://blog.jp.uwa4d.com
UWA公式Q&Aコミュニティ(中国語注意):https://answer.uwa4d.com
Unityリアルタイム反射に関する最適化
最適化後、プロジェクトの性能が確実にアップされました:8人が同時に接続+最高の画質で実行させるにもかかわらず、1.1ミリ秒しかかかりませんでした(Qualcomm Snapdragon710)。
そして、成功例として取り上げ、皆さんと私の最適化法を共有させていただいます。
ご参考になれば嬉しいです。
UnityのCompute Shaderの基本的な紹介と使用
最近、Compute Shader技術は広く利用されています。この前の『Moonlight Blade Mobile(天涯明月刀M)』や『Naraka: Bladepoint (中国語: 永劫无间)』テームは技術共有をしている時、よくCompute Shaderに言及していました。
そのゆえ、私のような初心者が数行のコードの意味を理解できるように、この記事を投稿しました。
Addressable基礎編シリーズ(8~9)
この記事は2つのセクションに分けられます。最初の部分において、この前にリリースしたAddressable基礎編シリーズ文章を簡単にまとめます。そして、リリースしていない第八と九の節を紹介します。
この前に公開したブログのタイトルと内容は以下のように示しています。
内容:Assetsとは何か、Assetsの識別と参照、Assetsのライフサイクル

内容:特別なプロジェクトディレクトリ、Resourcesの詳説、

内容:AssetBundleの仕組み、AssetBundleのローディング、AssetBundleからのアセットローディング

内容:ロードされたAssetsの管理、AssetBundleのリリース、Assetsの構成策、AssetBundleバリアント、AssetBundle圧縮、Crunch圧縮、

内容:Addressableのインストール、Addressable Assetsの用意、Addressable Assetsの使用法、ビルド、Addressableシステムのアップグレード

Addressable Assets管理、ビルドスクリプト、デバッグ、更新ワークフロー

Packed Modのテストと反復、設定、カスタムサービス

八、Addressable Assetsメモリ管理

8.1 ミラーリングロードとアンロード
Addressable Assets を使用する場合、適切なメモリ管理を確保するための主な方法は、ロードとアンロードの呼び出しを適切に管理することです。 やり方はアセットの種類や読み込み方法によって異なります。 ただし、すべての場合において、リリース メソッドは、読み込まれたアセットまたは Load によって返された操作ハンドルのいずれかを受け入れることができます。 たとえば、シーンの作成中 (以下で説明)、Load は AsyncOperationHandle を返し、この返されたハンドルを介して、またはハンドルを保持することによって、AsyncOperationHandle を同期的に解放します。
8.1.1 アセットのロード
アセットを読み込むには、Addressables.LoadAssetAsync または Addressables.LoadAssetsAsync を使用します。
これにより、アセットをインスタンス化せずにメモリにロードします。 ロード呼び出しが実行されるたびに、ロードされた各アセットに参照カウントが追加されます。 LoadAssetAsync を同じアドレスで 3 回呼び出すと、AsyncOperationHandle 構造体の 3 つの異なるインスタンスが作成され、すべて同じ基になる操作が参照されます。 この操作には、対応するアセットの参照カウントが 3 あります。 ロードが成功すると、結果の AsyncOperationHandle 構造の .Result プロパティにアセットが含まれます。 Unity の組み込みのインスタンス化メソッドを使用して、読み込まれたアセットでインスタンス化できます。これにより、Addressable の参照カウントが増加しません。
アセットをアンロードするには、Addressables.Releases メソッドを使用します。これにより、ref カウントが減少します。 特定の Asset の参照カウントがゼロになると、その Asset はアンロードされ、依存関係の参照カウントが減少します。
注: アセットは、既存の依存関係に応じて、すぐにアンロードされる場合とされない場合があります。
8.1.2 シーンのロード
シーンを読み込むには、Addressables.LoadSceneAsync を使用します。 このメソッドを使用して、開いているすべてのシーンを閉じるシングル モードでシーンをロードするか、追加モードでシーンをロードできます。詳細については、シーン モードのロードに関するドキュメントを参照してください。
シーンをアンロードするには、Addressables.UnloadSceneAsync を使用するか、シングル モードで新しいシーンを開きます。 Addressables インターフェイスを使用するか、SceneManager.LoadScene または SceneManager.LoadSceneAsync メソッドを使用して、新しいシーンを開くことができます。 新しいシーンを開くと、現在のシーンが閉じられ、参照カウントが適切に減少します。
8.1.3 ゲームオブジェクトのインスタンス化
GameObject アセットをロードしてインスタンス化するには、Addressables.InstantiateAsync を使用します。 これにより、指定されたアドレス パラメータによって配置されたプレハブがインスタンス化されます。 Addressable システムはプレハブとその依存関係を読み込み、関連するすべてのアセットの参照カウントを増やします。
同じアドレスで InstantiateAsync を 3 回呼び出すと、関連するすべてのアセットの参照カウントが 3 になります。 ただし、LoadAssetAsync を 3 回呼び出す代わりに、各 InstantiateAsync 呼び出しは、一意の操作を指す AsyncOperationHandle を返します。 これは、各 InstantiateAsync の結果が一意のインスタンスであるためです。 InstantiateAsync とその他の Load 呼び出しのもう 1 つの違いは、オプションの trackHandle パラメーターです。 false に設定すると、使用する AsyncOperationHandle をインスタンスの解放時に保持する必要があります。 これはより効率的ですが、より多くの開発作業が必要になります。
インスタンス化されたゲームオブジェクトを破棄するには、Addressables.ReleaseInstance を使用するか、インスタンス化されたオブジェクトを含むシーンを閉じます。 このシーンは Additive モードまたは Single モードでロード (およびクローズ) できます。 このシーンは、Addressable または SceneManagementAPI を使用してロードすることもできます。 前述のように、trackHandle を false に設定すると、Addressables.ReleaseInstance を実際の GameObject ではなく、ハンドルでのみ呼び出すことができます。
注: Addressables API を使用して作成されていないインスタンス、または trackHandle==false で作成されたインスタンスで Addressables.ReleaseInstance が呼び出された場合、システムはこれを検出し、メソッドが指定されたインスタンスを解放できなかったことを示す false を返します。 この場合、インスタンスは破棄されません。
InstantiateAsync には関連するオーバーヘッドがあるため、フレームごとに同じオブジェクトを何百回もインスタンス化する必要がある場合は、Addressables API を介して読み込み、次に他のメソッドを介してインスタンス化することを検討してください。 この場合、Addressables.LoadAssetAsync を呼び出してから結果を保存し、その結果に対して GameObject.Instantiate() を呼び出すことができます。 これにより、インスタンス化を同期的に呼び出す柔軟性が得られます。 欠点は、Addressable システムが作成したインスタンスの数を認識できないことです。これは、適切に管理されていないとメモリの問題を引き起こす可能性があります。 たとえば、テクスチャを参照するプレハブには、参照する有効な読み込まれたテクスチャがなくなり、バグ (またはクラッシュ) が発生します。 これらの問題は、メモリ GC をすぐにトリガーしない可能性があるため、追跡するのが困難です (メモリのクリアに関する以下のセクションを参照してください)。
8.1.4 データのロード
データの読み込みでは、AsyncOperationHandle.Result が発行するインターフェイスは必要ありませんが、操作自体を解放する必要があります。 たとえば、Addressables.LoadResourceLocationsAsync と Addressables.GetDownloadSizeAsync です。 リリース操作までアクセスできるデータをロードします。 このリリースは、Addressables.Releases で実行できます。
8.1.5 バックグラウンドでのやり取り
AsyncOperationHandle.Result フィールドに何も返さない操作には、完了時に操作ハンドルを自動的に解放するオプションのパラメーターがあります。 これらのアクション ハンドルの完了後にいずれかのアクション ハンドルが不要になった場合は、autoReleaseHandle パラメーターを true に設定して、アクション ハンドルが確実にクリアされるようにします。 autoReleaseHandle を false にするシナリオは、完了後にアクション ハンドルのステータスを確認する必要がある場合です。 これらのインターフェイスの例は、Addressables.DownloadDependenciesAsync と Addressables.UnloadScene です。
8.2 Addressables イベント ビューア
Addressables Event Viewer ウィンドウを使用して、すべての Addressable システム操作の参照カウントを監視します。 エディターでウィンドウにアクセスするには、[ウィンドウ] > [AssetManagement] > [Addressables] > [Event Viewer] を選択します。
注: イベント ビューアーでデータを表示するには、AddressableAssetSettings オブジェクトのインスペクターで SendProfilerEvents 設定を有効にする必要があります。
イベント ビューアには次の情報があります。
- 白い縦線は、ロード要求が発生したフレームを示します。
- 青色の背景は、現在読み込まれているアセットを示します。
- グラフの緑色の部分は、アセットの現在の参照カウントを表します。

8.3 メモリクリア時
参照されなくなったアセット (Analyzer の青色のセクションの終わりで示される) は、必ずしもアセットがアンロードされたことを意味するわけではありません。 一般的に適用されるシナリオには、AssetBundle 内の複数のアセットが含まれます。
例えば:
- 1 つの AssetBundle に 3 つのアセット (木、タンク、牛) があります。
- ツリーがロードされると、プロファイラーはツリーの参照カウントを表示し、AssetBundle は参照カウントを表示します。
- タンクがロードされると、プロファイラーはツリーとタンクのそれぞれに対して 1 つの参照カウントを表示しますが、AssetBundle に対しては 2 つの参照カウントを表示します。
- ツリーを解放すると、参照番号がゼロになり、青いバーが消えます。
この例では、ツリー アセットはこの時点では実際にはアンロードされていません。 AssetBundle またはその一部をロードできますが、AssetBundle を部分的にアンロードすることはできません。 バンドル内のアセットは、アセットバンドル自体が完全にアンロードされるまでアンロードされません。 このルールの例外は、エンジン インターフェイス Resources.UnusedAsset の呼び出しです。 上記のシナリオでこのメソッドを実行すると、ツリーがアンロードされます。 Addressables システムはこれらのイベントを認識する方法がないため、プロファイラー グラフには Addressable の参照カウントのみが反映されます (メモリ容量は反映されません)。 Resources.UnusedAsset の使用を選択した場合、これは非常に遅い操作であり、通常の表示に影響を与えない画面 (読み込み画面など) でのみ呼び出す必要があることに注意してください。
8.4 非同期操作ハンドル
Addressables API のいくつかのメソッドは、AsyncOperationHandle 構造を返します。 このハンドルの主な目的は、操作のステータスと結果にアクセスできるようにすることです。 操作の結果は、Addressables.Relace または Addressables.ReleaseInstance が呼び出されるまで有効です。
操作が完了すると、AsyncOperationHandle.Status プロパティは AsyncOperationStatus.Succeeded または AsyncOperationStatus.Failed になります。 成功した場合、AsyncOperationHandle.Result プロパティを介して結果にアクセスできます。
操作のステータスを定期的に確認したり、AsyncOperationHandle.Complete イベントを使用して完了したコールバックを登録したりできます。 返された AsyncOperationHandle 構造体によって提供されるアセットが不要になった場合は、Addressables.Releases メソッドを使用して解放する必要があります。
8.4.1 Type および .typeless ハンドル
ほとんどの Addressables API メソッドは、AsyncOperationHandle.Completed イベントと AsyncOperationHandle.Result オブジェクトのタイプ セーフを保証する汎用 AsyncOperationHandle 構造体を返します。 非ジェネリックの AsyncOperationHandle 構造もあり、必要に応じてこれら 2 つのハンドルを変換できます。
非ジェネリック ハンドルを不適切な型のジェネリック ハンドルにキャストしようとすると、実行時例外が発生することに注意してください。 例えば:

8.4.2 AsyncOperationHandleの使用例
AsyncOperationHandle.Completed コールバックを使用して、完了イベントのリスナーを登録します。

AsyncOperationHandle は IEnumerator を実装するため、コルーチンで生成できます。

Addressable は、AsyncOperationHandle.Task プロパティを介して非同期 await もサポートします。

AsyncOperationHandle.Task プロパティは WebGL では使用できません。WebGL ではマルチスレッド操作がサポートされていないためです。 allowSceneActivation を false に設定して SceneManager.LoadSceneAsync を使用するか、または activateOnLoad パラメーターを false に設定して Addressables.LoadSceneAsync を使用してシーンをロードすると、後続の非同期操作でロードの完了がブロックされる可能性があることに注意してください。 lowSceneActivation のドキュメントを参照してください。
8.5 カスタム操作の作成
IResourceProvider API を使用すると、データ駆動型の方法で場所と依存関係を定義することにより、読み込みプロセスを拡張できます。 場合によっては、カスタム アクションを作成したいことがあります。 IResourceProviderAPI は、これらのカスタム操作の上に内部的に構築されます。
カスタム操作を実装するには、AsyncOperationBase クラスから派生させ、必要な仮想メソッドをオーバーライドすることにより、カスタム操作を作成できます。 派生操作を ResourceManager.StartOperation メソッドに渡して操作を開始し、AsyncOperationHandle 構造を受け取ることができます。 この方法で開始されたアクションは ResourceManager に登録され、Addressables Event Viewer に表示されます。
- operationResourceManager を実行すると、カスタム操作のために AsyncO が呼び出されますoperationBase. メソッドの実行。
- 完了処理 カスタム操作が完了したら、カスタム操作オブジェクト AsyncOperationBase.Complete を呼び出します。 これは Execute メソッドで呼び出すことも、呼び出しの外に置くこともできます。 AsyncOperationBase.Complete を呼び出すと、操作が完了したことが ResourceManager に通知され、関連する AsyncOperationHandle.Completed イベントが呼び出されます。
- 操作の終了 AsyncOperationHandle を参照する AsyncOperationHandle を発行すると、ResourceManager はカスタム操作の AsyncOperationBase.Destroy メソッドを呼び出します。 ここで、カスタム アクションに関連付けられたメモリまたはリソースを解放する必要があります。
九、Addressablesアナライザー
Analyze は、プロジェクト アドレスのレイアウトに関する情報を収集するためのツールです。 場合によっては、アナライザーが適切なアクションを実行してアイテムの状態をクリーンアップすることがあります。 それ以外の場合、プロファイリングは、Addressable レイアウトについてより多くの情報に基づいた決定を下せるようにする純粋な情報ツールです。

9.1 Analyzeの使用
エディターで、Addressables Analyze ウィンドウを開く ([Window] > [Asset Management] > [Addressables] > [Analyze]) か、[Addressables Groups] ウィンドウから [Tools] > [Analyze] ボタンをクリックして開きます。
[Analyze] ウィンドウには、分析ルールのリストと次の操作が表示されます。
- Analyze Selected Rules(選択したルールを分析)
- Clear Selected Rules(選択したルールをクリア)
- Fix Selected Rules(選択したルールを修正)

9.1.1 Analyze Operation
Analyze Operationは、ルールの情報収集ステップです。 これをルールまたはルールセットで実行すると、ビルド、依存関係マップなどに関するデータが収集されます。 各ルールは、必要なデータを収集し、それを AnalyzeResult オブジェクトのリストとして報告する役割を果たします。
分析ステップ中は、データまたはプロジェクトの状態を変更するアクションを実行しないでください。 このステップで収集されたデータに基づいて、是正措置が適切な一連の措置である可能性があります。 ただし、一部のルールには分析ステップが 1 つしか含まれていません。これは、収集された情報に基づいて合理的、適切、かつ通常のアクションを実行できないためです。 Check Scene to Addressable Duplicate DependenciesとCheck Resources to Addressable Duplicate Dependenciesは、そのようなルールの例です (以下)。
純粋に情報提供のみを目的とし、修正アクションを含まないルールはUnfixable Rulesとして分類され、固定アクションを含むルールはFixable Rulesとして分類されます。
9.1.2 Clear step
このアクションは、分析によって収集されたすべてのデータを削除し、それに応じて TreeView を更新します。
9.1.3 Fix operation
修正可能なルールの場合、修正操作の実行を選択できます。 これは、分析ステップ中に収集されたデータを使用して、必要な変更を行い、問題を解決します。
分析で検出された問題を修正するために合理的で適切なアクションを実行できるため、Check Duplicate Bundle DependenciesはFixable Ruleの例の一つです。
9.2 提供されている分析ルール

9.2.1 修復可能なルール
9.2.1.1 重複するバンドル依存関係のチェック
このルールは、BundledAssetGroupSchemas を使用するすべてのグループをスキャンし、アセット グループのレイアウトを投影することによって、潜在的に冗長なアセットをチェックします。 これは実際には完全なビルドをトリガーするため、このチェックには非常に時間とパフォーマンスがかかります。
問題: 冗長なアセットは、異なるグループのアセットが依存関係を共有しているためです。 たとえば、2 つのプレハブが、異なるアドレス可能グループに存在するマテリアルを共有します。 これらのマテリアル (およびその依存関係) は、それぞれがプレハブを持つ 2 つのグループに分けられます。 これが起こらないようにするには、プレハブの 1 つまたは独自のスペースでマテリアルをアドレス指定可能としてマークし、マテリアルとその依存関係を単一のアドレス指定可能グループにグループ化する必要があります。
解決策: このチェックで問題が見つかった場合、このルールに対して FIX 操作を実行すると、新しい Addressable Group が作成され、すべての依存アセットが移動されます。
例外: 複数のオブジェクトを含むアセットがある場合、異なるグループは、コピーを作成する代わりに、アセットの一部のみを抽出できます。 多くのメッシュを含む FBX がその例です。 1 つのメッシュが「GroupA」にあり、別のメッシュが「GroupB」にある場合、このルールは FBX が共有されていると見なし、修復操作の実行時にそれを別のグループにアンパックします。 この場合、どちらのグループにも完全な FBX アセットがないため、FIX 操作の実行は実際には有害です。
また、冗長なアセットが常に問題になるわけではないことに注意してください。 アセットが同じユーザー グループ (地域固有のアセットなど) によって要求されない場合、冗長な依存関係が必要になるか、少なくとも冗長性は無関係です。 各アイテムはユニークでユニークです。 したがって、冗長なアセットの依存関係の修正は、ケースバイケースで評価する必要があります。
9.2.2 修復不可能なルール
9.2.2.1 アドレス可能な重複依存関係に対するリソースのチェック
このルールは、構築された Addressable データと Resources フォルダーに存在するアセットとの間にアセットまたはアセット依存関係の冗長性があるかどうかを検出します。
問題: これらの冗長性は、データがアプリ ビルドと Addressable ビルドの両方に含まれることを意味します。
解決策: 適切なアクションが存在しないため、このルールは修正できません。 これは単なる情報提供であり、冗長性を警告します。 分析された場合は、手動で解決する必要があります。 考えられる手動修正の例は、問題のあるアセットを Resources フォルダーから移動し、それを Addressable にすることです。
9.2.2.2 Check Scene to Addressable Duplicate Dependencies
このルールは、エディターのシーン リスト内のシーンと Addressable 内のシーンの間で共有されるアセットまたはアセットの依存関係を検出します。
問題: これらの冗長性は、データがアプリ ビルドと Addressable ビルドの両方に含まれることを意味します。
解決策: これは単なる情報提供であり、冗長性を警告しています。 分析された場合は、手動で解決する必要があります。 可能な手動修正の例は、参照が重複しているビルトイン シーンを BuildSettings から引き出し、それを Addressable シーンにすることです。
9.2.2.3 Check Sprite Atlas to Addressable Duplicate Dependencies
Addressable sprite atlasを指定すると、このルールは、アトラス内のスプライトが他の場所で Addressable としてマークされているかどうかを検出します。
問題: これらの冗長性は、スプライト データが Addressable ビルドの複数の領域で複製されることを意味します。
解決策: これは単なる情報提供であり、冗長性を警告しています。 分析された場合は、手動で解決する必要があります。 可能な手動修正の例は、アドレス可能から重複したスプライトを削除し、アセットがスプライトを直接参照するのではなく、アドレス可能スプライト アトラス内のスプライトを参照するようにすることです。
9.2.2.4 ビルド バンドル レイアウト
このルールは、Addressable ビルドで Assets を Addressable として明示的にマークする方法を示します。 これらの明示的なアセットについては、ビルドによって暗黙的に参照され、最終的にビルドに取り込まれるアセットも示します。
このルールの下で収集されたデータは、特定の問題を示すものではありません。 これは純粋な情報です。
9.3 Analyze拡張子
固有のプロジェクトごとに、事前にパッケージ化されたものだけでなく、追加の分析ルールが必要になる場合があります。 Addressable Assets System を使用すると、独自のカスタム ルール クラスを作成できます。
9.3.1 AnalyzeRule オブジェクト
AnalyzeRule クラスのサブクラスを作成し、次のプロパティをオーバーライドします。
CanFix: 分析ルールが修正可能と見なされるかどうかを示します。
ruleName 分析ウィンドウにルールを表示するために使用される名前。
次のように、次のメソッドをオーバーライドする必要もあります。
List RefreshAnalysis(AddressableAssetSettings settings)
void FixIssues(AddressableAssetSettings settings)
void ClearAnalysis()
注: ルールが修正不可能として指定されている場合、FixIssues メソッドをオーバーライドする必要はありません。
9.3.1.1 RefreshAnalysis
これが分析操作です。 この方法では、必要な計算を実行し、修復に必要なデータをキャッシュします。 戻り値はリストリストです。データを収集した後、分析のエントリごとに新しい AnalyzeResult を作成し、データを文字列として最初の引数として、MessageType を 2 番目の引数として使用します (オプションで、メッセージの種類を警告またはエラーとして指定します)。 作成されたオブジェクトのリストを返します。
特定の AnalyzeResult オブジェクトの TreeView に子要素を作成する必要がある場合は、kDelimiter を使用して親要素と子要素を記述することができます。 親と子の間に区切りを含めます。
9.3.1.2 FixIssues
これはあなたの修正です。 分析ステップに応じて適切なアクションを実行する必要がある場合は、ここで実行します。
9.3.1.3 ClearAnalysis
これがクリーンアップ操作です。 分析ステップ中にキャッシュされたデータは、この関数でクリアまたは削除できます。 TreeView は同時に更新され、必要なデータが不足していることを示します。
9.3.2 カスタム ルールを GUI に追加する
分析ウィンドウに表示するには、AnalyzeWindow.RegisterNewRule() を使用してカスタム ルールを GUI クラスに登録する必要があります。
Addressable基礎編シリーズは以上です。
投稿ありがとうございます。
投稿者の情報は以下です。
牛飼の星(放牛的星星)
Zhihu HP:https://www.zhihu.com/people/niuxingxing
UWA公式サイト:https://jp.uwa4d.com
UWA公式ブログ:https://blog.jp.uwa4d.com
UWA公式Q&Aコミュニティ(中国語注意):https://answer.uwa4d.com
Unityモバイルゲームパフォーマンス最適化略譜
「Unityモバイルゲームパフォーマンス最適化略譜」は、Unity モバイル ゲームの最適化に関するいくつかの基本的な議論から始まり、近年 Unity に基づいて開発されたモバイル ゲーム プロジェクトで最も一般的なパフォーマンスの問題のいくつかを例示および分析し、さらにUWA のパフォーマンステストツールを使用してこれらの問題を特定して解決する方法を示します。このコンテンツには、パフォーマンス最適化の基本的なロジック、UWA パフォーマンステストツール、および一般的なパフォーマンスの問題が含まれており、Unity 開発者により効率的な開発方法と実践的な経験を提供することを望んでいます。
本日は、5 つのサブセクションからなる第 1 部を紹介したいと思います。
- プレイヤーから見たゲームのパフォーマンス
- 開発者が気にするゲームのパフォーマンス
- 問題の特定方法
- 問題を解決する方法
- パフォーマンスを継続的に監視する方法
序文
1.プレイヤーから見たゲームのパフォーマンス
ゲームをプレイしているときに、どのプレイヤーも同様の質問に遭遇します: しばらくプレイするとクラッシュするのはなぜですか?ゲームがとても遅いのはなぜですか?なぜ私のスマホは熱くなったのでしょうか?バッテリーの減りが早いのはなぜですか?
プレイヤーにとって、ゲーム自体のアートが優れているかどうか、ゲームプレイが面白いかどうかにもかかわらず、これらの質問が発生すると、ゲーム体験は自然に悪化し、必然的に粘着性の低下につながります。これは、すべてのゲーム開発者が見たくない結果と言えますね。
実を言うと、私たちが現在注力しているモバイルゲーム市場は、国内市場でのさまざまなハードウェア モデルのパフォーマンスに幅があり、プロジェクトが海外市場をサポートする場合、プロジェクトが負担しなければならないパフォーマンス プレッシャーは多くの場合、より大きくなります。そのため、さまざまなハードウェア デバイスを使用するプレイヤー、特にミッドエンドからローエンドのデバイスを介してゲーム プロジェクトにアクセスできるプレイヤーが、ゲーム コンテンツをスムーズに体験できるようにする方法が、私たちの主な目標の 1 つです。
2.開発者が気にするゲームのパフォーマンス
ゲーム プロジェクトの開発プロセスでは、小規模または経験の浅い開発チームの場合、新しいプロジェクトの中期および初期段階で、パフォーマンスの最適化を無視して機能の実装に全力を注ぐことがよくあるという現象がよく見られます。プロジェクトにはゲームの体験に影響を与える多数の深刻なパフォーマンスの問題がいっぱいであることが判明したのは、ゲームの中期および後期段階、またはテストの開始間際でさえありましたが、時間が迫っていて、どこから始めればいいのかわからなくなります。パフォーマンスの問題がゲーム プロジェクトの重要な生命線で、開発者は、プロジェクトが迂回を回避できるように、適切な最適化の意識を確立し、知識システムを最適化する必要があります。
プレイヤーの視点とは異なり、開発者の視点からは、主にメモリ、CPU、GPUの3つのカテゴリーに分けられるべきだとUWAは考えています。この記事の主な内容は、ために、これら 3 つのカテゴリの一般的で典型的な問題を例示して説明する形で、モバイル ゲームのパフォーマンス最適化の概要を形成することを目的としています。
次に、いくつかのパフォーマンスの問題が見つかったため、問題の特定と解決が最も重要な 2 つのステップになりました。
3.問題の特定
パフォーマンスの問題が特定された後の最初の主要な手順は、問題を特定することです。
たとえば、ゲーム プロジェクトが長時間実行されるとクラッシュしますが、これはキャッシュ戦略が適切に行われていないためか、または冗長性があり、メモリの継続的な増加によってクラッシュが発生するためでしょうか?それとも、アート リソースのメモリ制御が不十分なため、いくつかのより大きなリソースでメモリ全体を簡単に拡張したのでしょうか?
あるいは、ゲーム シーンが非常にスタックしており、フレーム レートが非常に低いことが判明したのは、同じ画面でレンダリングされたパッチと DrawCall の数が多すぎて、レンダリング モジュールに高い負荷がかかっているためでしょうか?それとも、ここの UI が複雑すぎて頻繁に変化されるため、更新に時間がかかるのでしょうか?
それとも、、スマホが驚くほど熱くなっているのは現在のシーンでの GPU の負荷が高すぎるためでしょうか?帯域幅、シェーダーの複雑さ、オーバードロー、後処理などは十分に制御されていませんか?現在のデバイスで行っているグレーディング戦略は適切ではありませんか?
これらは、際限なく発生する無数のパフォーマンスの問題のほんの一部です。より一般的な問題のいくつかについては、後で詳しく説明します。結論として、問題を特定する作業自体が課題です。
3.1 コンピュータ言語/グラフィックス/ゲームエンジンの知識
知識と経験は、プロジェクトのパフォーマンスを最適化する際に開発者にとって間違いなく最も価値のある武器であり、継続的な学習と更新は、すべてのプログラマーが自分自身を武装させるためのプロセスでもあります。完璧で完全な知識は、問題を特定するのに役立つだけでなく、それらを解決するのにも役立ちます。これらの知識は最適化を開始するための重要な前提条件ですよね。
さまざまなツールのソース コードとドキュメントの閲覧、ツールの更新の追跡、すごい人が執筆した書籍の閲覧、さまざまなテクニカル フォーラムやブログの閲覧などに加えて、UWA ブログでは多くの質の高いコンテンツを見つけることができます。
UWAアカデミー(中国語注意):一部開発ツールの紹介と使い方からエンジンモジュールの仕組みや原理の詳細解説、最新のモバイルゲーム技術の実践からブティックプロジェクトの事例解説まで、質の高いコースを随時更新中などまた、業界で長年の経験を持つ多くの業界リーダーや有名ゲーム会社のパートナーを招待し、幅広い範囲と高品質をカバーする記事を執筆しました。UWA Technology が毎年主催するUWA DAY ゲーム開発者コンファレンス(中国語注意)の優れたコンテンツもあります。
UWA Q&A(中国語注意): 開発者がより良い答えを見つけられるように支援します。ゲーム開発者が技術的な問題を日常的にやり取りするための優れたプラットフォームです。ここでは、ゲーム制作のあらゆる側面について話し合ったり、質問に答えたりできます。回り道を回避し、現場で実証済みの開発経験を得るために最も直接的な技術交換を通じて、問題の特定と解決のプロセスがはるかに簡単になります。
UWA オープン ソース ライブラリ(中国語注意): 開発者がより優れたソリューションを見つけるのを支援します。さまざまなソースからのオープン ソース プロジェクトが継続的に更新および統合され、翻訳が完了し、分類が明確になり、写真とテキストが豊富になり、開発者がオープン ソース リソースを検索、発見、取得するためのより便利なチャネルが提供されます。
UWA ブログ: UWA が選んださまざまな技術記事が含まれており、UWAアカデミーに質の高いコンテンツを更新するよう促し、Q&A の質の高い質問を統合し、UWA 製品とその更新、その他の UWA コミュニティのトレンドを紹介しています。
3.2 各種補助ツール
大工がよい仕事をしようとすれば、まず道具をよく整えておかなければならない。ツールを使用して直接的で正確なパフォーマンス データを取得すると、パフォーマンスのボトルネックをより直感的に反映できるため、半分の労力で乗数効果を達成できます。
業界の発展と成熟に伴い、主要なエンジン、IDE、およびハードウェア メーカーは独自のパフォーマンス分析ツールをリリースおよび更新しており、多くの開発者またはチームは、独自のプロジェクトに従って独自のパフォーマンス監視プラグインを開発することを好みます。
エンジンに関する限り、Unity Profiler は多くの開発者が使用しているツールであり、CPU/レンダリング/メモリなどのさまざまなモジュールのリアルタイムの消費パラメーターを記録および表示できます。 Unreal 4 では、同様の機能が既に利用可能です。
IDE に関しては、Windows、MAC OS/iOS、および Andriod プラットフォームのすべてに、Visual Studio のパフォーマンス プロファイラー、XCode の Instruments、Android Studio の Profiler などの適切なツールがあります。
ハードウェア的には、SnapDragon Profiler、XCode Metal Frame Capture、Mali Graphics Debugger など、他にも種類があるが、一々くどくど述べません。
まとめすると、開発者の習熟度、さまざまなハードウェア プラットフォームの互換性、ツール機能の適用範囲など様々な要素に応じて、適切なパフォーマンス最適化ツールの選択はめんどくさくなります。
3.3 UWA ツール
では、使いやすく、強力な互換性を持ち、包括的な機能を備えたパフォーマンス最適化ツールはありますか?
もちろんあります。
UWA GOT Online ツールは、UWA が提供する SDK を介してテスト プロジェクトにすばやく統合できます. 実機でのテスト プロセスが完了した後、データのアップロードと分析は非常に短い時間で完了し、ビジュアルチャートのシリーズを自動的に生成できます。同時に、UWA の豊富な最適化経験と評定用の巨大なデータベースにも基づいており、各パフォーマンス モジュールに応じてターゲットを絞った分析の提案とパフォーマンス パラメータの変化トレンドを提供します。
それだけでなく、UWA は GPM、GOT、実機テスト サービス、オンライン アセットバンドル検出、ローカル リソース検出、GPU 特別レポート、詳細な最適化などのツールやサービスも提供し、さまざまな次元から開発者の最適化ニーズに応えます。
4.問題の解決方法
パフォーマンスにおける 2 番目の大きなステップは、問題解決です。知識と経験、および上記のツールのサポートにより、プロジェクトがより複雑になり、後期になるほど、最適化の問題の長いリストに直面することになります。限られた時間の中でこのリストを適切に計画し、短縮することが次の課題です。
4.1 作業優先度の最適化
特定の最適化作業を始める前に、適切な計画を立てることは全体的な時間を大幅に節約できます。
計画作業の最初のポイントは、問題の主要な矛盾を把握することです。長い最適化リストでは、各項目を順番に最適化することは多くの場合非現実的です。この時点で、リストを再編成し、優先順位を付けて並べ替え、費用対効果の高い問題を最適化するためにより多くの投資を行う必要があります。
優先度の判断について、UWA は 2 つの主要な基準点があると考えています: 第一に、重要性です。現在のシーンのパフォーマンスへのプレッシャーが他の要因よりもはるかに大きな影響を与える問題は、明らかに主な矛盾です。問題を修正しない場合、正常のゲーム体験を維持することは困難です。それに対して、まずために、より多くの人力や時間を投資して集中して問題を解決する必要があります。第二に、操作の易さです。パフォーマンスへのプレッシャーがそんなに大きくないが、コストが低くて解決しやすい問題ならすぐに修正すべきです。例えば、エンジン設定でたった一つのスイッチをオフにするだけ済むのような問題の場合、すぐに直すべきだと思われます。
4.2 性能と効果のトレードオフ
2 つ目のポイントはトレードオフで、リソースとレンダリングの最適化はゲームのパフォーマンスに影響を与えることがよくあります。そのため、プログラマーは多くの場合、プランナーやアーティストの同僚とのコミュニケーションを強化して、2 つの間のバランスを見つける必要があります。このバランスは動的なバランスであり、実際の状況に合わせて運用する必要があります。例えば、『Game for Peace』ゲームは頻繁な画面切り替えとスムーズな戦闘操作が必要なため、パフォーマンス要件は低くてもかまいません。しかし、育成ゲームは精巧なキャラクターを売りにし、いくつかのパフォーマンスを犠牲にしてモデルやアニメーションは非常に繊細である必要があります。同じゲームでも、カットシーンやキャラクター表示インターフェースでは表現に集中し、戦闘シーンならパフォーマンスに集中すべきです。要するに、特定の問題に対して特定の分析が必要です。
一般に、ゲーム プロジェクトの最適化の最終的な目標は、プレーヤーのハードウェア上でスムーズに実行することであり、このためにパフォーマンスへの影響の大部分を放棄することは、ほとんどの開発チームの実際の選択でもあります。
4.3 格付け戦略と基準設定
第三に、各タイプのスマホで上記のバランスを達成することが、私たちのグレーディング戦略です。ハイエンド モデルやフラッグシップ モデルでは後処理をオンにして高解像度を使用できますが、ミッド・ローエンドのモデルでは異なる標準セットを使用します。
グレーディング戦略を策定するには、プロジェクトの種類に応じて調整する必要もあります。より詳細で正確なグレーディングについては、プロジェクトのターゲット市場のハードウェア モデルと類似ゲームの経験も参照する必要があります。詳細については、記事「モバイル デバイス コンピューティングに基づく UWA パフォーマンス標準システム」(中国語注意)を参照してください。
さらに、開発チームは、開発プロセス全体を管理および制約するための一連の詳細で合理的な基準を指定することもできれば望ましいです。最も一般的なのは、アート リソースの標準を指定することです。これにより、暴走するメモリの問題を大幅に回避できます。また、Unityにはコールバック関数のリソースインポート時の正規化設定も用意されており、詳しくはUWA Academyの関連講座「Unity Resources for Standardizationの自動化の実践」(中国語注意)も参照してください。
4.4 UWA からの提案
計画が完了した後、具体的な最適化作業が行われます。これは退屈な作業であり、忍耐が必要です。UWA はその過程で喜んでお手伝いします。
UWA コミュニティで方法を探すか、UWA ツールの自動レポートで解決策を見つけることができます。また、UWA サポートに連絡して、実機テスト レポートに関する 1 対 1 の説明サービスや、さらに詳細な最適化サービスを提供することもできます。 UWA のエンジン技術チームは、ゲーム プロジェクトのより詳細な診断と提案を行います。
5.パフォーマンスを継続的に監視する方法
パフォーマンス最適化の最初の 2 つのステップを実行した後、多くの開発チームは、パフォーマンスを継続的に監視するステップである 3 番目のステップを希望しています。この目的のために、一部のチームは専用のエンジン オプティマイザーを持ち、独自の DevOps ツールを開発しようとしています。これは、ゲーム開発の「工業化」の流れの表れであると考えています。
5.1 ゲーム研究開発の工業化
中国での高品質なゲームの需要が年々高まる中、プロジェクト開発の「工業化」に対するゲーム開発チームの要求も高まっています。 UWA の見解では、ゲーム開発の「工業化」は現在、標準化、正規化、専門化、自動化、およびカスタマイズの 5 つの次元に分けることができます。過去 2021 年に、UWA は上記の側面で多くの作業を行い、多くの経験を蓄積してきました。
2022年、UWA Technologyが主催するゲーム開発をテーマにした第6回UWA DAY Technology Conferenceで、UWAは「ゲーム開発の工業化を実践する」というテーマに固執し、業界の開発者を率いて優れた開発理念と実践的な経験をを味わいながら、業界パートナーと協力して、オープンでウィンウィンの技術交換エコシステムを構築します。
この背景に、UWA は UWA Pipeline 2.0 バージョンをリリースしました。これは、ゲーム開発チーム向けのローカル コラボレーション プラットフォームであり、ゲーム開発チーム専用の DevOps 開発 デリバリー パイプラインを構築することを目的としています。
5.2 UWA パイプライン
UWA パイプラインには主に次のものが含まれます。
専用の DevOps 開発 デリバリー パイプライン
プライベート クラウド実機リモート デバッグ
自動テストを視覚的に構成する
Pipeline で UWA サービスをすばやく作成する
リモートビルドのサポート
5 つの機能は、ゲーム専用に設計された DevOps 開発 および配信パイプラインを提供し、さまざまな UWA ツールとサービスを統合して、構築と操作を簡単にします。詳細については、以下をクリックしてください。
「UWAパイプラインの活用と自動化パイプラインの構築を詳しく解説」
この記事の内容はここで紹介されています. より多くのコンテンツについては、UWAアカデミーにアクセスして読むことができます。このコースでは、現在のゲーム プロジェクトでよく発生するパフォーマンスの問題について、メモリ、CPU、GPU の 3 つの側面から説明します。
UWA公式サイト:https://jp.uwa4d.com
UWA公式ブログ:https://blog.jp.uwa4d.com
UWA公式Q&Aコミュニティ(中国語注意):https://answer.uwa4d.com